
平时不温不火只当笔记记录的博客,这几天突然流量爆增,从一天不到100的访问量增到了一天2~3k。
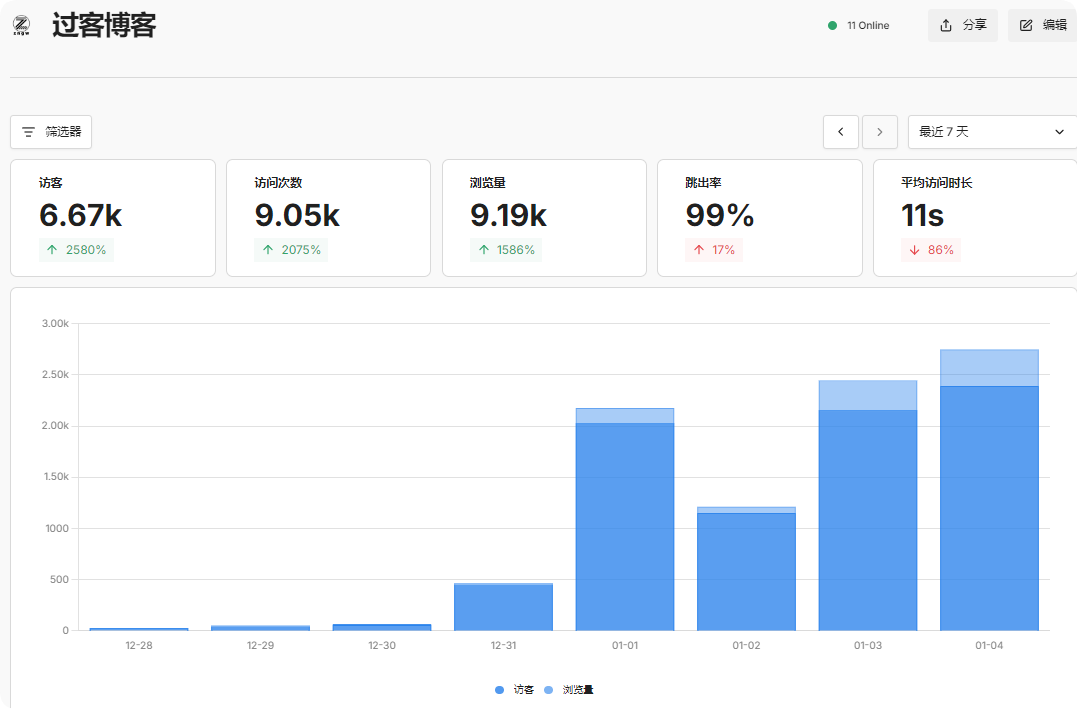
从Umami的分析以及Nginx日志来看:
-
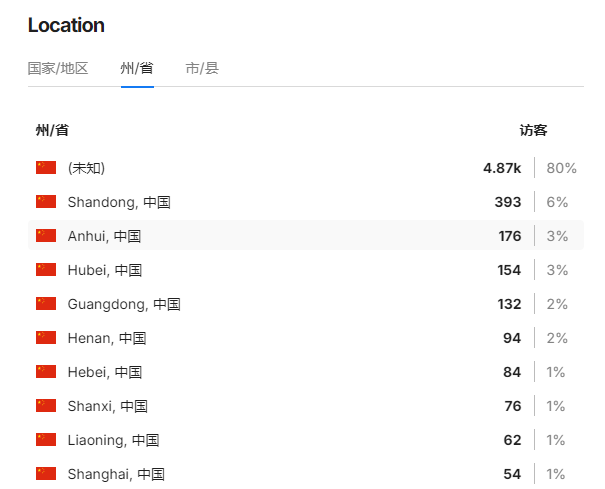
- 80%流量来自IPv6,前缀判断为中国
-
- 剩余10%的IPv4分析地域为全国各地都有
-
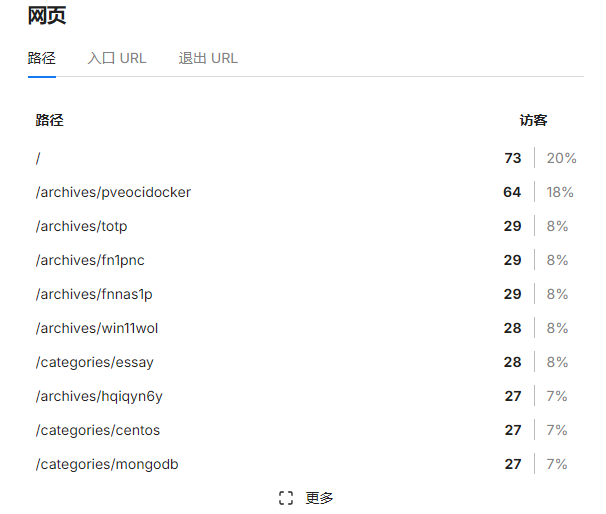
- 95%来源于直接访问
-
- 文章浏览较平均,没有某一篇特别突出
-
- 日志中并没有报错、404等报错。
-
- User-Agent 看似正常,但高度可疑
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.7499.170 Safari/537.36
通过以上种种数据和日志分析,感觉我的博客被高度疑似 AI 训练数据爬虫(或大规模内容聚合爬虫)。
日志中出现多个不同的中国电信 IPv6 地址(如 240e:f7:..., 2409:8a... 等),每个 IP 通常只访问一次或几次,这是典型的“分布式低频爬虫”策略——避免被按 IP 封禁。访问路径呈现“全站遍历”特征,感觉是根据站点地图(sitemap.xml)来遍历的,而且单个 IP 请求频率不高,但 IP 总数多(日志中至少 10+ 个不同 IPv6),累计造成 2k+/日 的 PV。这正是当前(2025–2026)AI 数据公司抓取中文技术博客的标准手法:用海量家庭宽带或云主机 IPv6 出口,模拟浏览器,低频遍历高质量站点。
我这博客何德何能能被AI爬虫光顾,仔细看了一下网站设置的robots.txt文件,发现貌似允许爬取哈😕
User-agent: *
Allow: /
Disallow: /console
Sitemap: https://zengwu.com.cn/sitemap.xml
虽然恶意爬虫会无视 robots.txt,但部分正规数据集采集方(如 Common Crawl)会遵守,防君子不防小人哈。
算了,不处理就这样吧,只要不是被黑客攻击就行。这也就浪费点宽带(平时也没啥流量),至于内容被盗用,本来就是公开的,只要能遵循“CC BY-NC-SA 4.0 共享协议”就没问题。


评论区