
今天在使用Hermes的时候出现模型调用失败,进入New-API中转服务器发现,CPU已经爆了,SSH命令都卡。

这个New-API是使用1Panel部署的,用起来是挺简单的,但容器安装多了,也会有坑,配置不是太高的情况下,容器业务本身不繁忙时,Docker daemon(dockerd)持续占用极高 CPU(90%+)。
问题想象
- top / htop 显示 dockerd 占用 90%+ CPU
- 大量 dockerd 子线程在频繁访问 /run/containerd/containerd.sock
- docker events 中每隔几秒就出现大量 exec_create / exec_start / exec_die 事件
- 服务器主要安装了Halo博客套件(Halo、Umami、PostgreSQL、Redis、 meilisearch、openresty)以后后面又加了 哪吒监控、New-API等
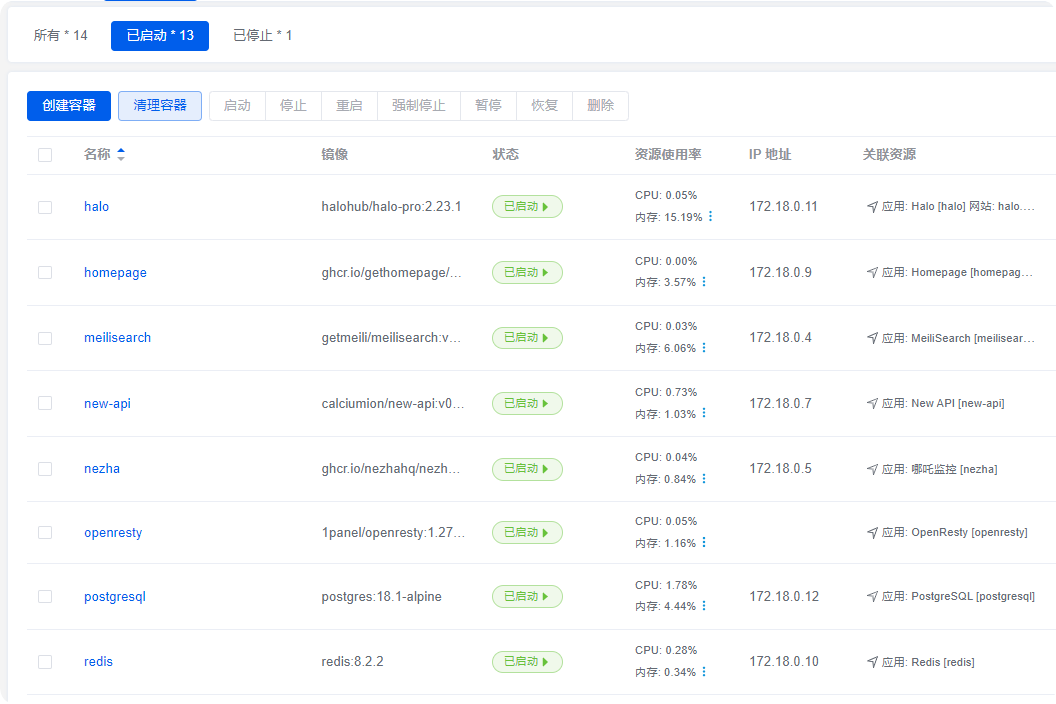
问题分析
1. 查看容器自身 CPU 使用情况
docker stats --no-stream
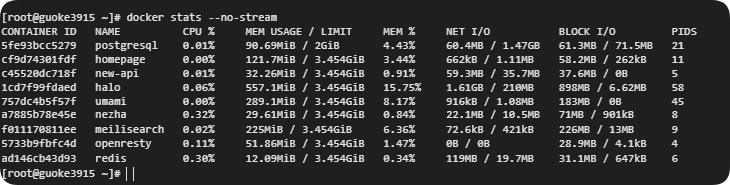
可以看出,容器自身使用CPU并不高
2. 日志分析
查找损坏的日志文件,如果有损坏日志,IO会导致CPU过高
find /var/lib/docker/containers/ -name "\*-json.log" -exec bash -c 'jq . {} > /dev/null 2>&1 || echo "损坏文件: {}"' \\;
如果有损坏日志,直接删除吧,删了不会对现有容器产生影响,但一些历史日志记录就没了。
# 一键删除所有损坏的日志文件
find /var/lib/docker/containers/ -name "\*-json.log" -exec bash -c 'jq . {} > /dev/null 2>&1 || rm -f {}' \\;
还可以在 /etc/docker/daemon.json 中添加日志轮转配置:
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3",
"compress": "true"
}
}
3. 查看最近的 Docker 事件(重点看 healthcheck)
# 按Ctrl+C中断输出
docker events --since '10m'
日志文件很长,可以直接丢给AI去分析,像我的是
- umami 每 5~10 秒执行 curl .../heartbeat
- homepage 每 10 秒执行 wget .../healthcheck
- halo 每 10~30 秒执行 curl .../actuator/health/readiness
- postgresql 每 30 秒执行 pg_isready
- new-api 每 30 秒执行复杂检查命令
这个健康有点频繁了,docker缺省健康检查是30秒,这个明显是1panel的docker-compose.yml中有调整过,我们可以改久一点,设置60s左右。以umami为例,其他容器类似
# 进入容器目录
cd /data/1panel/apps/umami/umami
# 编辑 docker-compose.yml
vim docker-compose.yml
# 找到healthcheck项,配置interval
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/api/heartbeat"]
interval: 60s
timeout: 10s
retries: 3
start_period: 30s
# 也可以禁用健康检查
healthcheck:
disable: true
- 重启
docker compose down && docker compose up -d
这顿操作下来,发现cpu只降了10%左右,现在cpu占用还在80%左右。继续往下分析:
4. dockerd 线程分析
- 接下来用工具分析 dockerd 线程详细情况
# 若未安装
yum install htop -y
htop

能看到 多个containerd.sock 的 dockerd 线程占用CPU过高。
- 使用perf查看dockerd在执行什么函数
# 安装perf
yum install perf -y
# 实时看 dockerd 的热点函数(按 CPU 排序)
perf top -p $(pgrep dockerd)
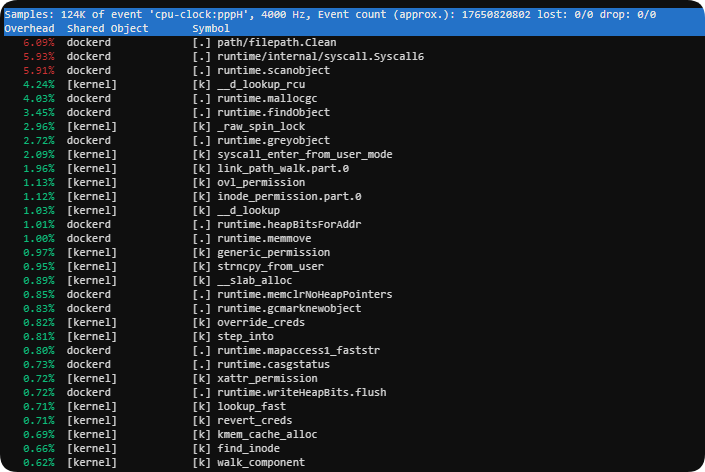
从日志中可以看出,dockerd 正在疯狂进行 overlay2 文件系统相关的元数据操作(路径查找、权限检查、inode 操作、内存分配等),占用大量 CPU(前几位都是 path/filepath.Clean、runtime/internal/syscall.Syscall6、runtime.mallocgc、runtime.greyobject、runtime.findObject 等 Go 运行时垃圾回收和对象管理函数)。这是 Docker + overlay2 的已知高负载场景,尤其在容器频繁创建/销毁(1Panel 典型行为)后容易出现。
这种情况,即使把所有容器停了,CPU的占用情况也会居高不下。所以,彻底重置 Docker 所有元数据,再重装,注意这是重装重装重装,最好提前备份好数据。
# 1. 停止所有容器
docker stop $(docker ps -q) 2>/dev/null || true
# 2. 删除所有容器(不删 volume,这是保留数据,而且1Panel中容器数据都是映射到主机目录中的,所以,不出意外数据是保留的,为了保险起见,做好数据备份是有必要的)
docker rm -f $(docker ps -a -q) 2>/dev/null || true
# 3. 强制卸载残留 overlay mount
for m in $(mount | grep -E 'overlay|docker' | awk '{print $3}'); do
umount -f -l $m 2>/dev/null || true
done
# 4. **彻底清理 overlay2(关键步骤)** —— 这会删除所有残留层,dockerd 重启后会为新容器重建
# 彻底重置 Docker 元数据(保留 /var/lib/docker/volumes/ 里的数据)
rm -rf /var/lib/docker/image/*
rm -rf /var/lib/docker/containers/*
rm -rf /var/lib/docker/overlay2/*
rm -rf /var/lib/docker/buildkit/*
# 5. 重启docker服务
systemctl restart containerd
systemctl restart docker
# 6. 重启1Panel
1pctl restart
最后进入1Panel,直接选择重建,不出意外的话,重新成功,所有数据还在。
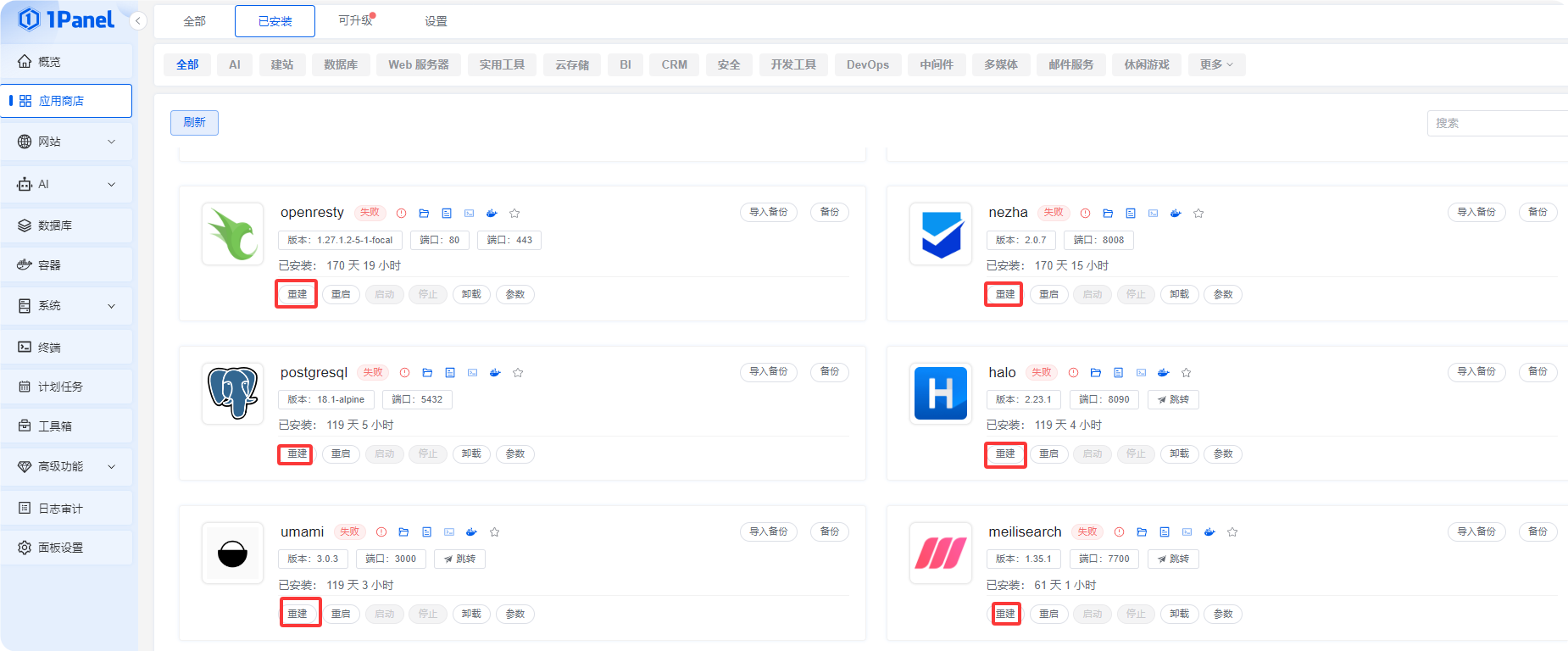


评论区