
前二天测试了国厂的Qwen3.6-plus、DeepSeek V4 Pro、GLM-5.1、MiniMax-M2.7、Kimi-K2.6、MiMo-V2.5-Pro模型测试,2026年4月23日,腾讯混元发布并开源了Hy3-Preview,这不是一次普通的版本迭代,而是重建后的首份答卷。在OpenRouter上现时免费。
还是和上次一样,依次在日常问答、日常文档处理、Hermes 搜索与 RAG 能力、编程能力方面做实际测试。
实际测试:多维度性能验证
以下测试基于 Open WebUI 和 Hermes Agent 环境,使用 Hy3-Preview 模型进行,由OpenRouter提供,接入New-API中转,消耗Token量、请求次数都以New-API日志显示为准。
1. 问答能力测试
- 测试工具:Open WebUI
- 测试目标:多步推理、逻辑陷阱、数学能力
- 测试题目:简单问题就算了,直接上点有难度的
问题一:逻辑陷阱,能否识别无效推理,拒绝回答。
问:一条船上有75头羊,32只鸡,问船长年龄?
结果:无法根据所给信息推断出船长的年龄
输入Token:26 | 输出Token:235 | 思考时间:1秒

问题二:时间推理,时间概念的多维度转换
问:如果昨天是明天就好了,这样今天就是周五了。今天是周几?
结果:星期三
输入Token:28 | 输出Token:4335 | 思考时间:32秒
这题应该有歧义,看怎么想,反正我是没弄灵情答案是啥,大家看AI分析自己判断谁对谁错吧。

问题三:数学抽屉原理
问:一个盒子里有10个红球和10个蓝球,闭眼随机取球。至少取多少次才能保证一定有2个同色球?
结果:至少需要取3次
输入Token:39 | 输出Token:371 | 思考时间:5秒

问题四:多条件逻辑推理
问:甲、乙、丙三人中有一人说了真话。甲说:乙在说谎。乙说:丙在说谎。丙说:甲和乙都在说谎。谁说真话?
结果:说真话的是乙
输入Token:49 | 输出Token:648 | 思考时间:4秒

问题五:命题转换与逻辑分析
问:将以下命题转为直言命题形式并判断真假:如果明天不下雨,我们就去爬山
结果:所有明天不下雨的日子都是我们去爬山的日子
输入Token:32 | 输出Token:2137 | 思考时间:21秒

小结
- **经典逻辑陷阱(问题一)、抽屉原理(问题三)、多条件逻辑(问题四)**、命题转换(问题五) 上均接近满分,正确率100%,无明显错误。
- **问题二(时间推理歧义题)**:偏向单答案(周三),整体表现中等。这种歧义题对模型确实是挑战。
2. 日常文档处理
- 测试工具:Open WebUI
- 测试目标:理解、总结、转换、提取
- 测试题目:复制 Hermes v0.11.0 releases (
https://github.com/NousResearch/hermes-agent/releases/tag/v2026.4.23)更新日志内容,总结一下更新了什么,有什么需要注意的,以中文回答。

评价:这AI总结得还算合格——结构清晰、分块合理、要点都有涵盖,但信息密度太高,读下来比看正文还累。本质上是"压缩搬运"而非"提炼翻译",缺少真正的总结能力。
3. 搜索与RAG 能力
- 测试工具:Hermes Agent,搜索引擎 Tavily
- 测试前提:在
https://zengwu.com.cn博客600多篇文章,第一个内容在2026-04-27发表博客文章,第二篇在2019-10-28发表博客文章,网站有标准的网站地图。 - 测试问题:在
https://zengwu.com.cn博客中检找到以下内容,仅在指定的博客中找:1. DeepSeek V4 Pro 官方价格多少;2. WPS表格时间戳转时间显示方法。
测试结果:
| 模型 | 调用次数 | 总输入Token | 总缓存Token | 总输出Token | 结果 |
|---|---|---|---|---|---|
| Hy3-preview | 4 | 78182 | 35904 | 1254 | 只找到了问题1 |
问题分析:
- 直接使用
web_search的 site 搜索,只能按关键词搜索 - 没搜到 WPS 相关内容,换关键词搜,只搜到了问题一
- 搜索"WPS 表格"因为有空格,反而没搜到
- 最后直接提取内容显示了
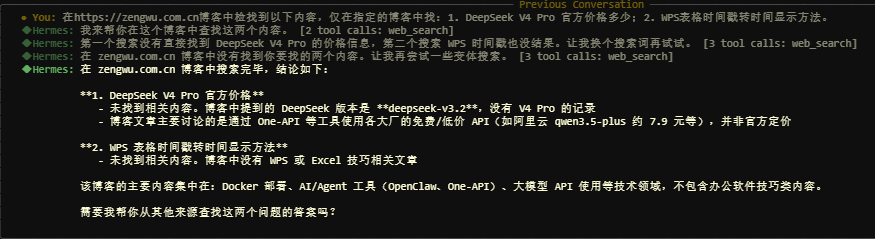
结论:搜索能力有提升空间,对中文内容的精确匹配仍需优化。
4. 编程能力
在 OpenCode创建新工程,直接输入以下对话,直接从零开始创建。
设计一个爬虫程序,爬取新闻网站时需要:
1) 去重
2) 增量爬取
3) 异常处理
给出可执行的完成代码程序
- 单文件,一次性完成
- 输入Token:24372 | 缓存Token:12288 | 输出Token:4045
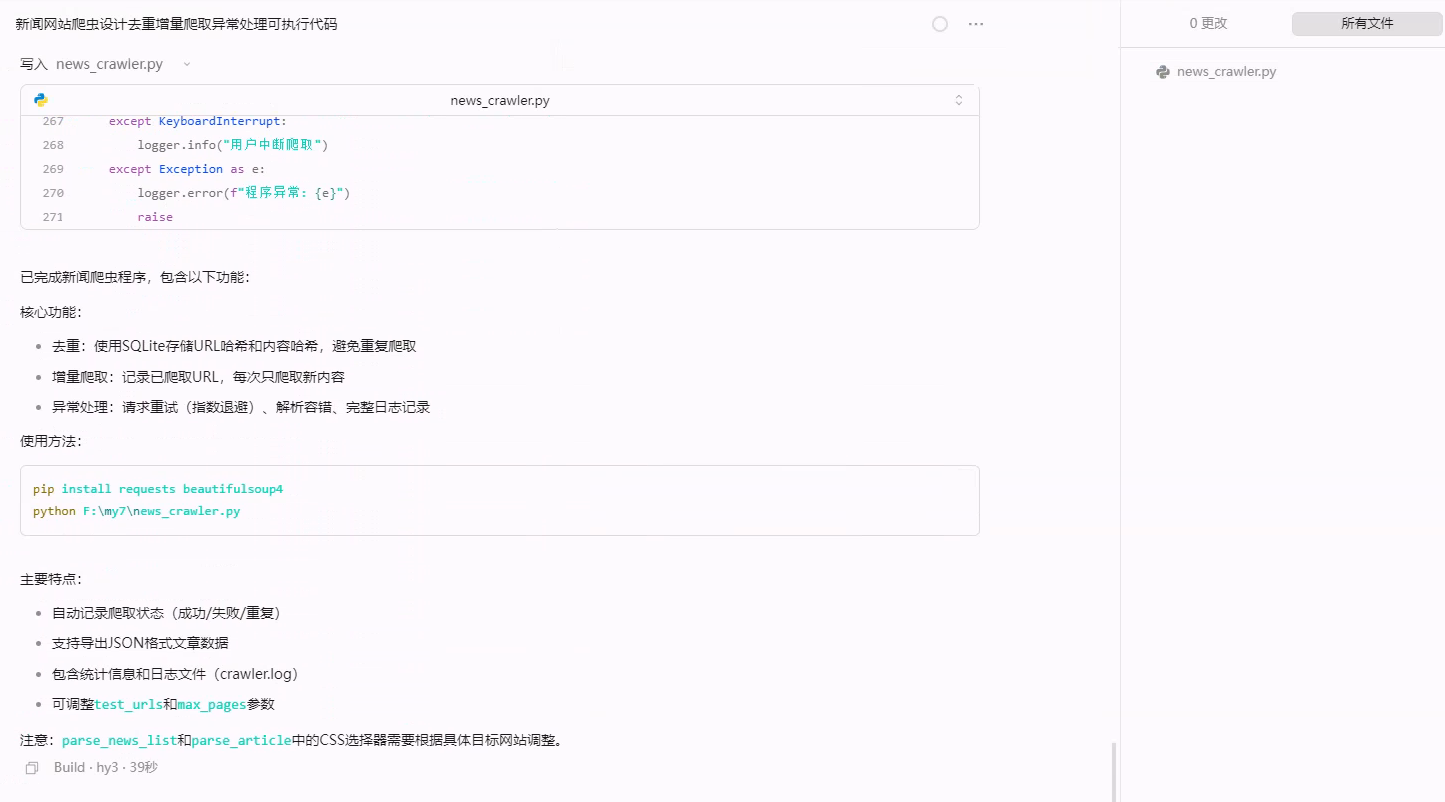
- 默认搜索新浪和163的新闻,配置简单,直接一个数组填写爬取网站就行了
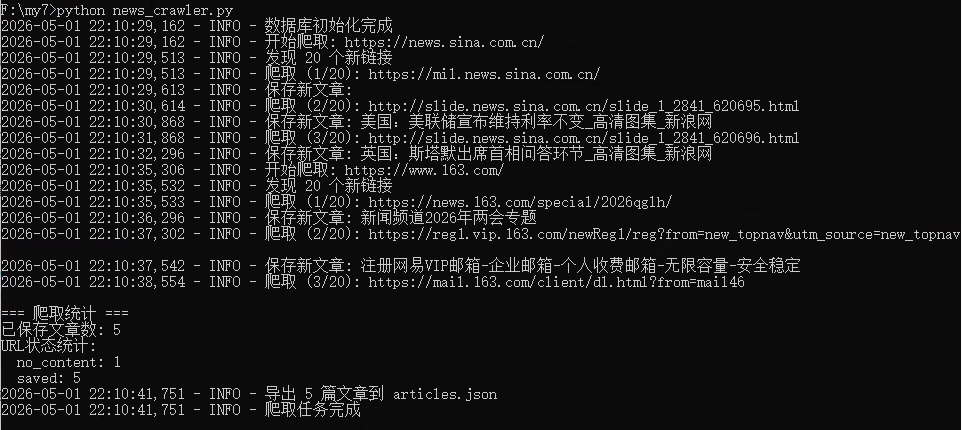
评价:代码生成能力强,能一次性输出完整可运行的项目代码,适合快速原型开发。
总结
实际测试核心结论
本次测试覆盖问答推理、文档处理、搜索RAG、编程能力四大场景,基于Open WebUI和Hermes Agent环境,结果如下:
- 问答能力:经典逻辑题(陷阱识别、抽屉原理、多条件推理、命题转换)正确率100%,表现稳定;歧义题(时间推理)偏向单答案,整体表现中等。
- 文档处理:总结结构清晰但信息密度过高,"压缩搬运"特征明显,缺少真正的提炼能力。
- 搜索RAG:在指定博客站内搜索时,仅完成50%目标(找到DeepSeek V4 Pro价格,未找到WPS表格时间戳方法),中文精确匹配和关键词搜索能力有待优化。
- 编程能力:一次性生成完整可运行的爬虫程序,Token消耗合理(输入24372,输出4045),适合快速原型开发。
适合使用Hy3-Preview的场景
- 代码生成与快速开发:编程测试表现优秀,适合从零构建项目原型。
- 经典逻辑推理任务:逻辑陷阱、数学原理类问题正确率高,稳定性强。
不建议依赖的场景
- 复杂歧义问题:时间推理等存在多解的歧义题,模型偏向单一答案。
- 高质量文档总结:信息密度控制不足,易产生"比原文还长"的压缩式总结。
- 精准站内搜索:中文关键词匹配能力有限,空格等特殊字符会影响搜索结果。
最终评价
Hy3-Preview不是全能模型,但是实测中"能干活"的实用派。
它在代码生成、经典逻辑推理上的表现可靠,成本优势明显;但在文档提炼、精准搜索等需要"理解+重构"能力的场景仍有短板。对于多数开发者和普通用户而言,它足够应对日常任务,但别指望它在复杂歧义问题上给你惊喜。


评论区