
周五晚上睡觉前翻了翻 OpenRouter,本想看有没有什么新模型测试的,并没发现什么,然后看了看排行页面,越看越有意思,干脆拉了一份完整数据出来分析一下。
先说数据来源。OpenRouter 是个 LLM 中间商,用户通过它调用各种模型,它把用量数据全公开了。虽然不能代表全球所有 LLM 用量,但作为行业风向标够用了——毕竟上面跑了上百个模型,涉及几百万用户,一周光 token 就烧掉 22T(万亿)级别。
本周 Top 10:一周烧掉的 token 比你一辈子说的话还多
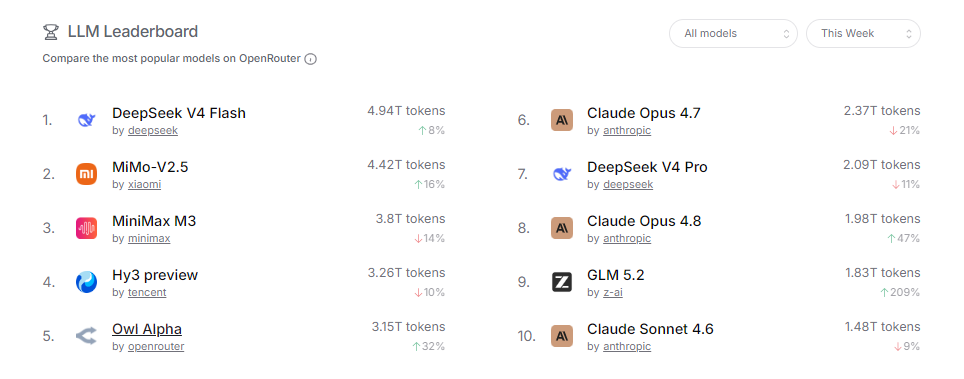
| 排名 | 模型 | 厂商 | 周 Token | 周变化 |
|---|---|---|---|---|
| 1 | DeepSeek V4 Flash | DeepSeek | 4.94T | +8% |
| 2 | MiMo-V2.5 | 小米 | 4.42T | +16% |
| 3 | MiniMax M3 | MiniMax | 3.8T | -14% |
| 4 | Hy3 Preview | 腾讯 | 3.26T | -10% |
| 5 | Owl Alpha | OpenRouter | 3.15T | +32% |
| 6 | Claude Opus 4.7 | Anthropic | 2.37T | -21% |
| 7 | DeepSeek V4 Pro | DeepSeek | 2.09T | 11% |
| 8 | Claude Opus 4.8 | Anthropic | 1.98T | +47% |
| 9 | GLM 5.2 | 智谱 | 1.83T | +209% |
| 10 | Claude Sonnet 4.6 | Anthropic | 1.48T | -9% |
前四名全是国产模型。第一名 DeepSeek V4 Flash 一周烧了将近 5T token,什么概念?就是如果你一个人每天 24 小时不停地跟它聊天,大概要聊 300 万年才能烧完它一周的量。
更离谱的是 GLM 5.2,**一周暴涨 209%**。大概率是智谱最近降价或者新发布了什么功能。国产模型的玩法就是这样:先靠低价把量铺开,再慢慢养生态。
厂商格局:钱流向了哪里
看 token 量,中国厂商加起来占了快一半:
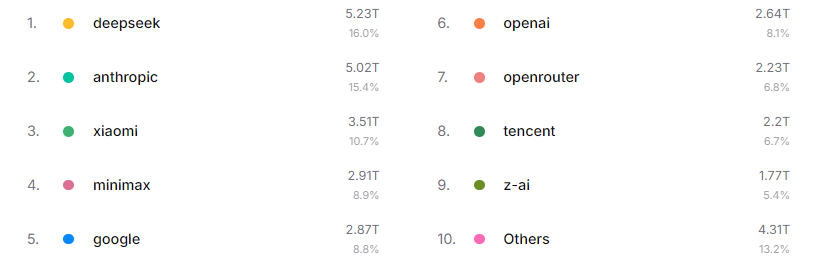
有篇英文报道的标题很直白——"Chinese AI Models Overtake US Rivals in Global Token Consumption"。2026 年 2 月开始中国模型就反超了,到现在差距还在拉大。
但这里面有个坑。
Token 多 ≠ 赚得多
回头看一下 Top 10 里 Anthropic 的价格:Claude Opus 4.7 输入 5/M tokens,输出 25/M tokens。而 DeepSeek V4 Flash 输入 0.09/M tokens,输出 0.18/M tokens——价格差了 50 到 138 倍。
所以如果用「收入」而不是「token 量」来排,Anthropic 大概率是第一。量大的模型靠走量,贵的模型靠高客单价,两边都活得挺好。
真正有意思的:任务分布
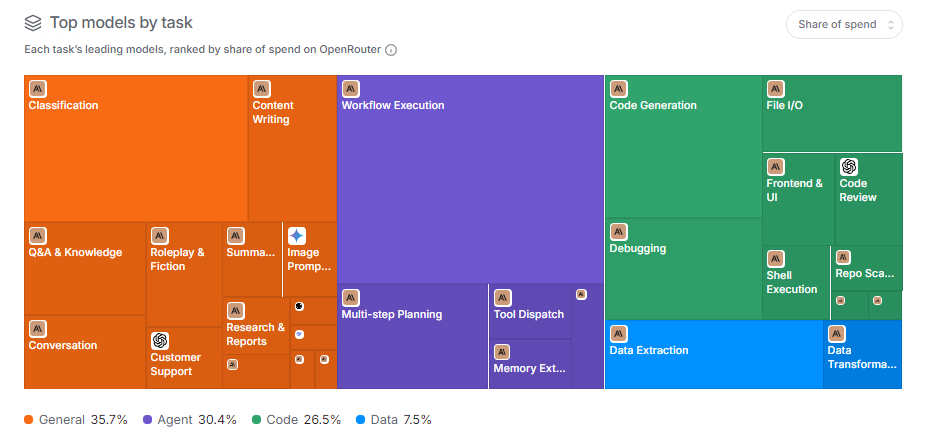
OpenRouter 把请求分成了四大类:
- **General(通用)**:35.7%
- **Agent(智能体)**:30.4%
- **Code(代码)**:26.5%
- **Data(数据)**:7.5%
Agent 吃掉 30.4% 的 token 这件事,其实解释了为什么国产模型能在总量上赢。Agent 场景的特点是:单次任务 token 消耗巨大。一个简单的编程任务,Agent 能烧掉 2000 万 token(来回推理、工具调用、长上下文)。普通问答可能就几千 token。
这就导致:Agent 和代码类应用天然倾向选便宜模型,反正大部分 token 是上下文和中间推理,不是最终答案。用户感受不到质量差异,但成本差了几十倍。
质量 vs 数量:一张错位的排行榜
最有意思的来了。按 token 总量,Anthropic 排第二。但 OpenRouter 还有另一个维度——按任务类型排头号模型。
我把所有任务分类的头号模型列出来:
| 任务类型 | 第一名 | 任务类型 | 第一名 |
|---|---|---|---|
| Classification | Claude | Code Generation | Claude |
| Content Writing | Claude | Debugging | Claude |
| Q&A & Knowledge | Claude | File I/O | Claude |
| Conversation | Claude | Frontend & UI | Claude |
| Summarization | Claude | Shell Execution | Claude |
| Research & Reports | Claude | Repo Scanning | Claude |
| Finance & Trading | Claude | SQL & Database | Claude |
| Math | Claude | DevOps | Claude |
| Security Audit | Claude | Data Extraction | Claude |
| Multi-step Planning | Claude | Data Transformation | Claude |
| Tool Dispatch | Claude | Memory Extraction | Claude |
| Web Search | Claude | Workflow Execution | Claude |
足足 24 个分类,全都是 Claude 第一。DeepSeek 只在 Roleplay & Fiction 拿了第一,OpenAI 包了 Customer Support、Translation、Code Review,Google 拿了 Image Prompting。
这就很说明问题了——真正干活的时候,大家还是掏钱选 Claude。高价值场景的用户容错率低,不在乎那点 API 差价。但在角色扮演、闲聊这些「不差就行」的场景,便宜模型碾压。
Top Apps:Agent 工具才是 Token 吞噬兽
顺便看了下 Top Apps 排行榜,这些是选择公开用量的第三方应用:
| 排名 | 应用 | 类型 | 周 Token |
|---|---|---|---|
| 1 | Hermes Agent | AI Agent | 7.33T |
| 2 | Kilo Code | 代码工具 | 1.82T |
| 3 | OpenClaw | AI Agent | 1.25T |
| 4 | Claude Code | 代码工具 | 1.01T |
| 5 | Descript | 视频编辑 | 528B |
| 6 | Cline | 代码工具 | 470B |
| 7 | pi | 代码工具 | 462B |
| 8 | Pioneer | API 推理 | 355B |
| 9 | Janitor AI | 角色扮演 | 245B |
| 10 | ISEKAI ZERO | 角色扮演 | 236B |
Hermes Agent 一个应用一周烧了 7T多 token——比 Anthropic 总量的一半还多。Agent 类工具正在变成真正的 Token 吞噬兽。
说说我的看法
这周数据看完,几个感想:
- 国产模型赢在跑量,输在场景深度。 Token 量好看,但赚不到高价值场景的钱。有点像安卓和 iPhone——安卓出货量大,iPhone 拿走行业 80% 利润。
- Agent 化是最大的变量。 当单任务从几千 token 飙升到几百万 token,价格敏感度会急剧上升。这对国产模型是利好——但前提是质量不能掉队。
- Anthropic 的优势可能被低估了。 在几乎所有「正经干活」的分类里拿第一,这不是偶然。一旦 Agent 从实验阶段进入生产环境,用户会发现「便宜但老出错」比「贵但靠谱」贵得多——修复一次错误的 token 成本可能就超过一整周的差价了。
- 个人用的话,现在的策略很明确:日常问答和角色扮演用 DeepSeek/GLM 等国产模型,便宜量大管饱;写代码、做研究、处理重要任务还是 Claude/GPT 更靠谱。
- OpenClaw 排第三挺意外的。作为一个开源项目,能在应用排行榜压过 Claude Code,说明「连接所有消息通道 + 主动执行」这个定位踩中了。


评论区