
CodingPlan 时代正在收尾,TokenPlan 成了各家主推的方向。问题来了:名字都叫 Token Plan,但计费规则完全不一样。阿里用 Credits 折算,腾讯直接按 Token 扣,小米搞了个倍率体系——同样用 100 万 token,三家扣的额度能差好几倍。
这篇把阿里百炼、腾讯云、小米 MiMo 三家的 Token Plan 拆开讲清楚,重点聊计费公式和实际使用中的坑。
一、三家计费逻辑速览
先放结论,后面逐个展开:
| 对比项 | 阿里百炼 Token Plan | 腾讯云 Token Plan | 小米 MiMo Token Plan |
|---|---|---|---|
| 计量单位 | Credits(折算值) | Tokens(原始 token 数) | Credits(折算值) |
| 输入 vs 输出 | 输出 6 倍 | 1:1 等价 | 输出2倍 |
| 缓存命中 | 输入价的 1/10 | 1:1 等价 | 输入价的1/50~1/120 |
| 不同模型 | 动态折算,贵模型吃更多 | 不区分,统一抵扣 | 区分,按模型倍率 |
| 5 小时限额 | 无 | 无 | 无 |
一句话总结:阿里最复杂,腾讯最简单粗暴,小米有倍率陷阱但缓存最便宜。
二、阿里百炼 Token Plan
套餐与价格
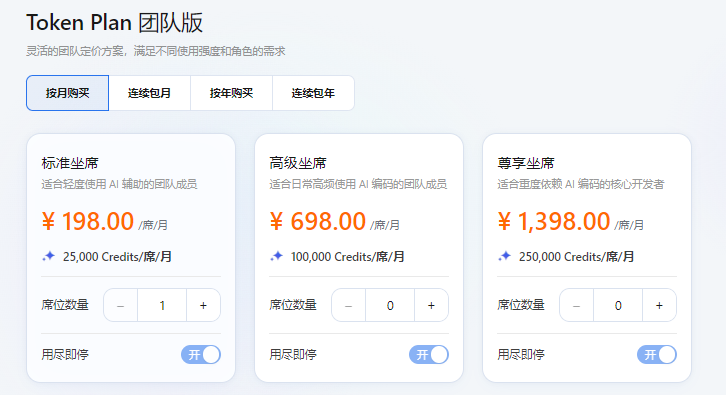
计费公式
Credits = 输入 Tokens × 模型输入系数
+ 缓存 Tokens × 模型缓存系数
+ 输出 Tokens × 模型输出系数
+ 思考模式额外消耗
+ 工具调用额外消耗
官方只给了 qwen3.6-plus 一个示例:
| Token 类型 | 数量 | 消耗 Credits | 反推单价 |
|---|---|---|---|
| 输入 | 8,349 | 1.67 | 200 Credits/M |
| 缓存 | 40,794 | 0.82 | 20 Credits/M |
| 输出 | 573 | 0.69 | 1,200 Credits/M |
换算关系:
- 缓存 = 输入价的 1/10
- 输出 = 输入价的 6 倍
- 1 Credit ≈ 5,000 Tokens(按 qwen3.6-plus 基准)
支持模型
Qwen3.7-Max(限时 Credits 减半)、Qwen3.6-Plus/Flash、DeepSeek-V4-Pro/V3.2、GLM-5.1、MiniMax-M2.5、Kimi-K2.6 等 10+ 款。
由于 Credits 本质是按按量计费价格折算的,可以用各家的 API 定价来推算 Credits 消耗比例(估算仅供参考,具体以账单为准):
| 模型 | API 输入价 | API 输出价 | 相对 qwen3.6-plus | 估算 Credits 消耗倍数 |
|---|---|---|---|---|
| qwen3.6-plus | ¥2/百万 | ¥12/百万 | 1x(基准) | 1x |
| qwen3.7-plus | ¥2/百万 | ¥8/百万 | ≈ 0.71x | ≈ 0.71x |
| qwen3.7-max | ¥2/百万 | ¥36/百万 | ≈ 2.71x | ≈ 2.71x(限时减半 → 1.355x) |
| DeepSeek-V4-Pro | ¥3/百万 | ¥6/百万 | ≈ 0.64x | ≈ 0.64x |
| DeepSeek-V4-Flash | ¥1/百万 | ¥2/百万 | ≈ 0.21x | ≈ 0.21x |
| GLM-5.1 | ¥6/百万 | ¥24/百万 | ≈ 2.14x | ≈ 2.14x |
| MiniMax-M2.5 | ¥2.1/百万 | ¥8.4/百万 | ≈ 0.75x | ≈ 0.75x |
| Kimi-K2.6 | ¥6.5/百万 | ¥27/百万 | ≈ 2.39x | ≈ 2.39x |
优势
- 模型最多:10+ 款模型随便切,一个套餐体验全生态
- 缓存便宜:命中缓存只要 1/10 Credits,长上下文场景(代码库分析、长文档)划算
- 无 5 小时限额:不像 Coding Plan 那样被时间窗口卡脖子
- 企业级功能:团队管理、席位分配、用量分析、数据不训练
坑
- Credits 折算不透明:官方只给了 qwen3.6-plus 的示例,其他模型的 Credits 消耗"以账单为准"。你想算清楚 GLM-5.1 或 DeepSeek-V4-Pro 消耗多少 Credits?只能自己调了看账单
- 输出贵:输出 token 的 Credits 消耗是输入的 6 倍。Agent 场景下输出量大,实际消耗远超预期
- 思考模式额外扣费:开启深度思考或联网搜索,Credits 消耗会额外增加,具体多少没公开
- 不支持自动化脚本:仅限交互式使用,禁止 API 批量调用或后端集成,违规可能封号
三、腾讯云 Token Plan
套餐与价格
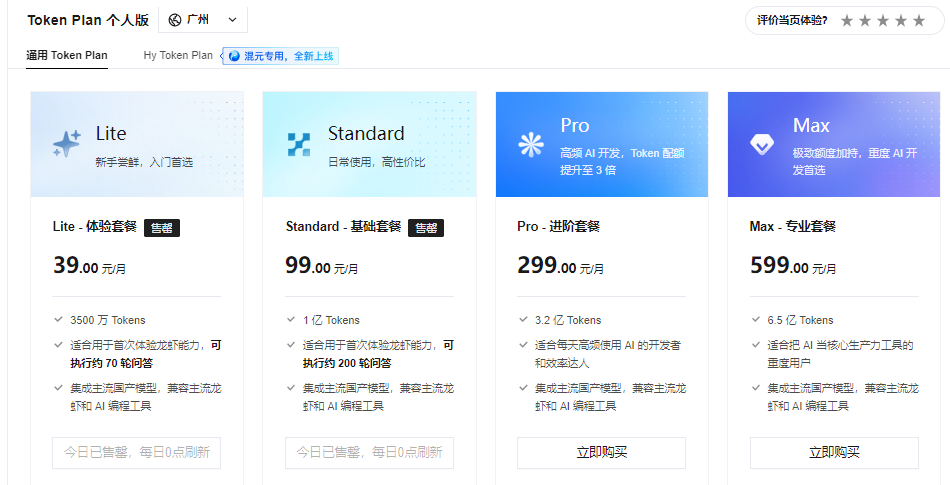
通用 Token Plan(支持 Auto、MiniMax、GLM、Kimi 等):
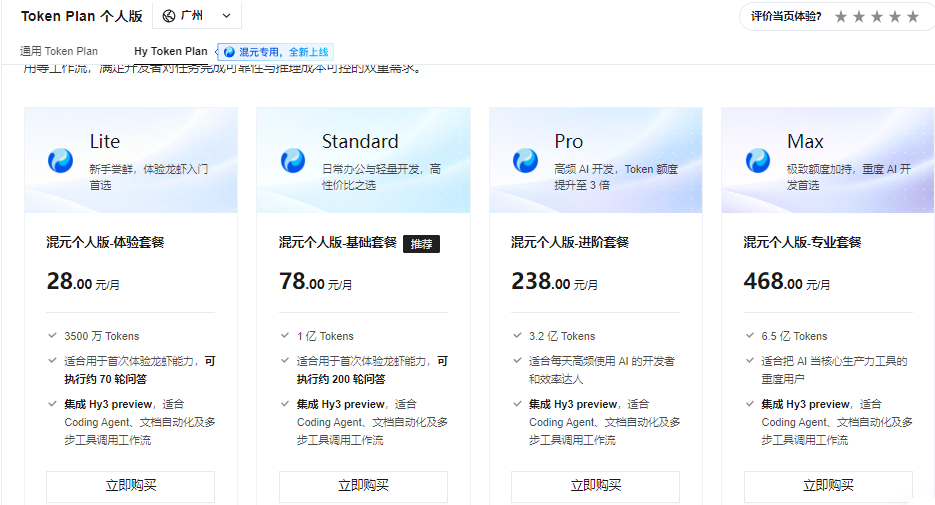
Hy Token Plan(混元专属,便宜约 25-30%):
计费公式
消耗 Token = 输入 Tokens + 缓存命中 Tokens + 输出 Tokens
没有系数,没有倍率,没有模型区分。1 个输入 token = 1 个输出 token = 1 个缓存 token = 1 Token 额度。
支持模型
Auto(智能路由)、MiniMax-M2.5/M2.7、GLM-5/5.1、Kimi-K2.5、Hy3 preview 等。
优势
- 最简单:不分模型、不分输入输出、不分缓存,用多少扣多少,零学习成本
- 薅贵模型羊毛:GLM-5.1 和 MiniMax-M2.5 消耗一样的额度,但 GLM-5.1 单价更贵——用贵模型等于赚到了
- Hy 版更便宜:混元专属版比通用版便宜 25-30%,如果只需要一个模型,性价比极高
- 无 5 小时限额:支持集中消耗
坑
- 缓存不打折:和阿里不同,腾讯的缓存命中 Token 和输入 1:1 扣除,长上下文场景没有阿里划算
- 额度用完即停:不支持续费补额度,到期后 API Key 失效,剩余额度不结转
- Lite/Standard 限额低:3,500 万额度,按 OpenClaw 场景约 70 轮对话,认真用两天就没了
- Hy 版模型少:只支持 Hy3 preview 一个模型,灵活性差
- 即将下线部分模型:Tencent HY 2.0 Instruct/Think、Hunyuan-T1 等 6 月 22 日下线
四、小米 MiMo Token Plan
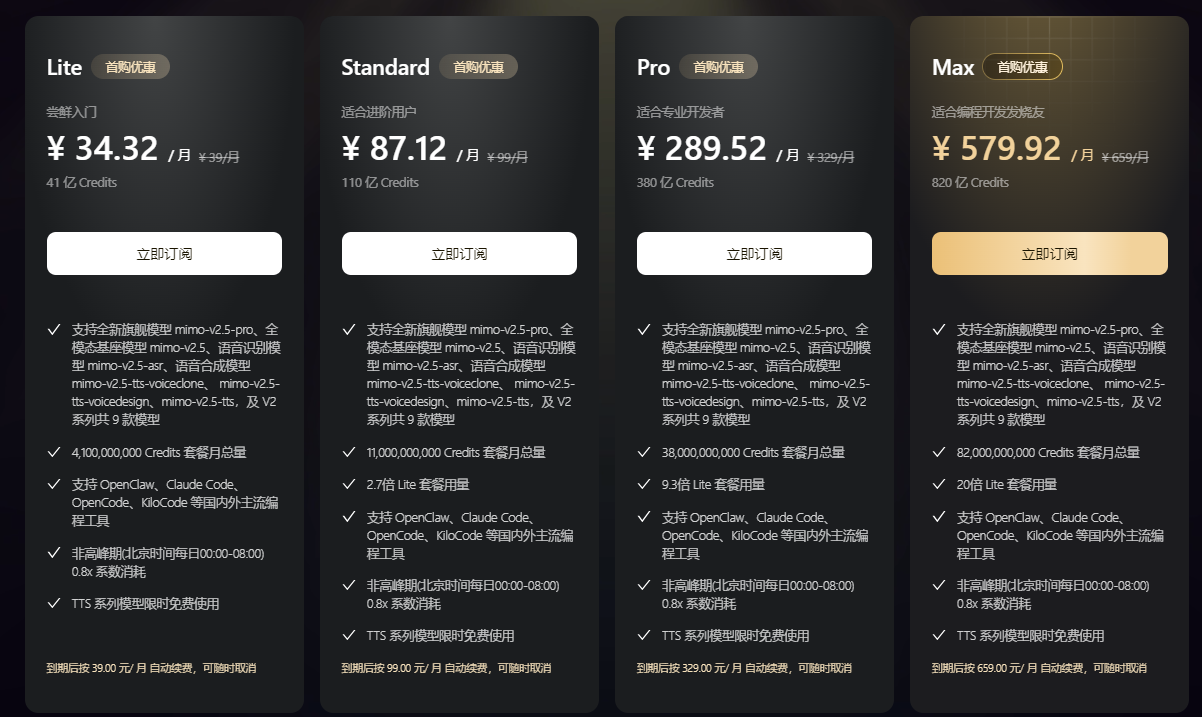
套餐与价格
计费公式
Credits = 输入 Tokens × 模型输入系数
+ 缓存 Tokens × 模型缓存系数
+ 输出 Tokens × 模型输出系数
语言模型
| 模型 | 输入(命中缓存)Token | 输入(未命中缓存)Token | 输出 Token |
|---|---|---|---|
| mimo-v2.5-pro | 2.5 Credits | 300 Credits | 600 Credits |
| mimo-v2.5 | 2 Credits | 100 Credits | 200 Credits |
| mimo-v2-pro | 2.5 Credits | 300 Credits | 600 Credits |
| mimo-v2-omni | 2 Credits | 100 Credits | 200 Credits |
ASR 模型
| 模型 | 输入音频时长(h) |
|---|---|
| mimo-v2.5-asr | 30M Credits |
支持模型
MiMo-V2.5-Pro(旗舰)、MiMo-V2.5(全模态基座)、MiMo-V2.5-ASR 等 9 款模型。
注意:mimo-v2-pro、mimo-v2-omni 于北京时间 2026.6.1 00:00 自动转发至 V2.5 系列,并按 V2.5 系列的比例消耗 Credit,最终于 2026.6.30 00:00 正式下线。 建议尽快切换至新版模型。
优势
- 额度巨大:5 月更新后 Lite 就有 41 亿 Credits,Max 160 亿,字面上碾压同行
- 无 5 小时限额:支持集中消耗
- 缓存超便宜:mimo-v2.5 pro缓存比1/120倍,mimo-v2.5 缓存比1/50倍,命中缓存Token基本可以说是免费送。
坑
- 倍率陷阱:字面 41 亿 Credits 听着多,但 Pro 模型 输入(未命中)、输出 都几百倍率,实际只有 1300万输入未命中Token,或700万输出Token。
五、三家怎么选?
场景一:轻度体验 / 预算有限
推荐:腾讯云 Lite ¥39 或 Hy Lite ¥28
理由最简单:便宜、好算、够用。3,500 万 token 对新手足够,Hy 版更便宜。
场景二:日常开发 / 多模型切换
推荐:阿里百炼标准坐席 ¥198
10+ 款模型随便切,缓存便宜,适合想横向对比不同模型的开发者。
场景三:重度编程 / GLM 5.1 场景
推荐:腾讯云 Max ¥599
- 腾讯:6.5 亿 token 不分模型不分类型,使用GLM 5.1 模型不涨价。
六、避坑指南
- 先算后买:别被字面额度迷惑,阿里看 Credits 折算、小米看倍率、腾讯看 token 数,三家算法完全不同
- 缓存是省钱关键:阿里缓存 1/10、腾讯缓存 1:1、小米1/50 ——如果你的场景缓存命中率高,小米最划算
- 输出控制:阿里输出 6 倍消耗,Agent 场景下输出量大时要特别注意
七、总结
Token Plan 的本质是把算力成本转化为可预测的月费。但"可预测"的前提是你得搞清楚各家的计费规则。阿里赢在模型多,腾讯赢在简单直接,小米赢在缓存便宜。
选哪家不重要,重要的是——别被字面数字骗了。


评论区