
前几天说了OpenClaw省Token神器QMD与MemOS对比与使用,然后也查过一些资料,也问过千问,说OpenClaw 内嵌了QMD核心功能,需再额外安装。OpenClaw只集成了QMD的检索功能,并没有数据的嵌入生成。所以检索了个寂寞。
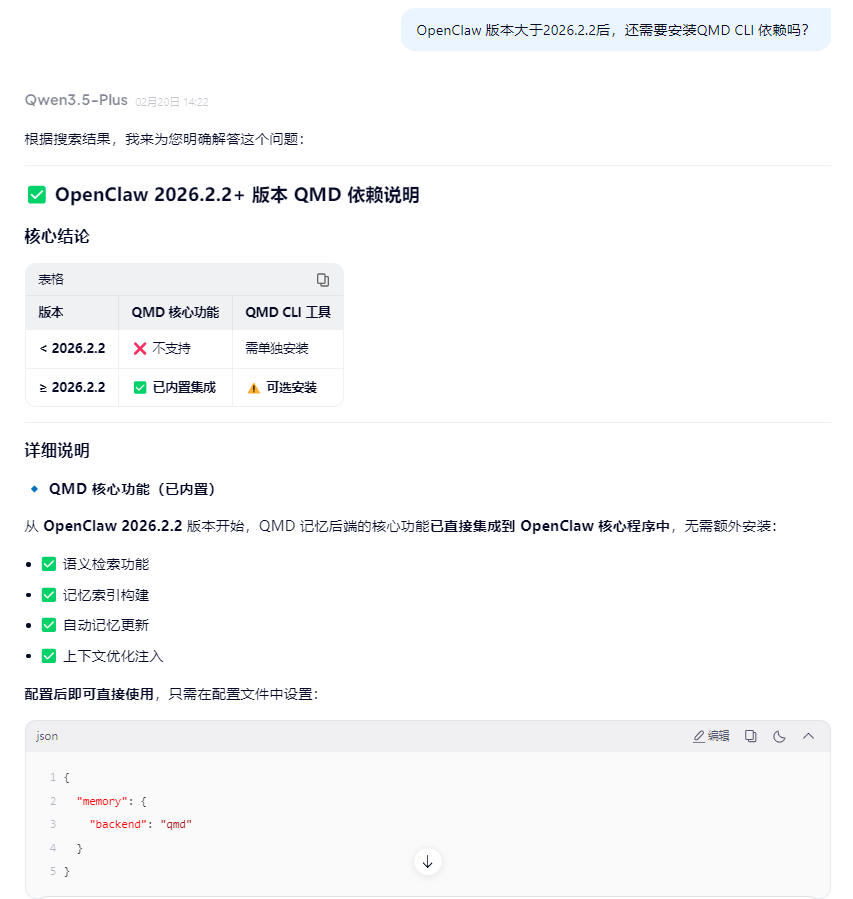
然后用openclaw memory status查询状态,显示运行也正常
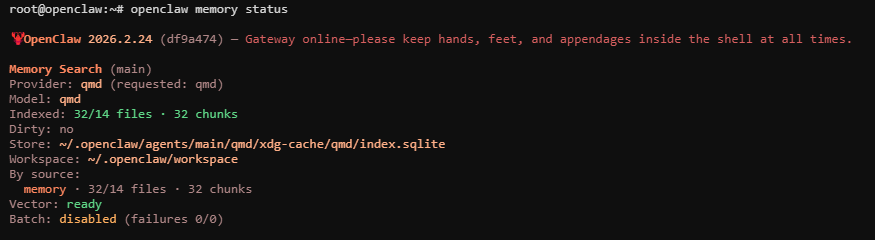
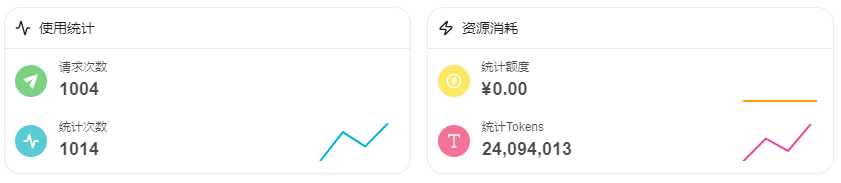
结果重点来了,几天断断续续使用了一下,发现token消耗了1400多万的Token,但请求数并不多只有可怜的几百次。
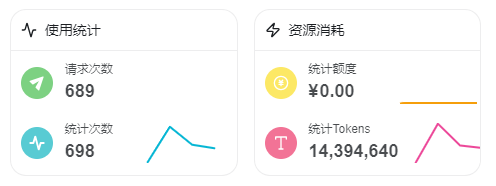
查看日志发现,都是输入都是3万多的token(我设置的contextWindow参数为33K),这不就表明qmd基本没啥用,基本被contextWindow裁剪的。
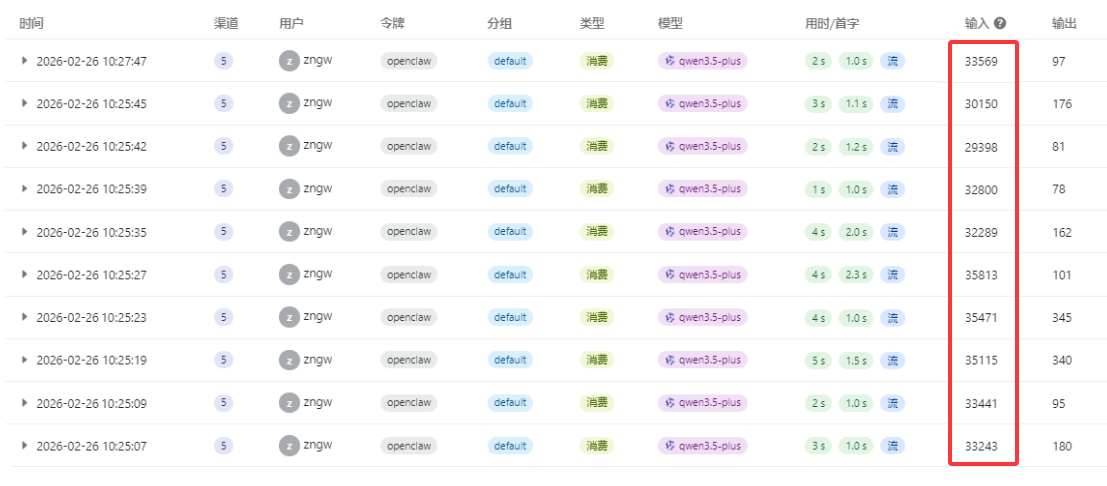
然后用openclaw自己检查一下,发现,真没启用,还需要安装qmd
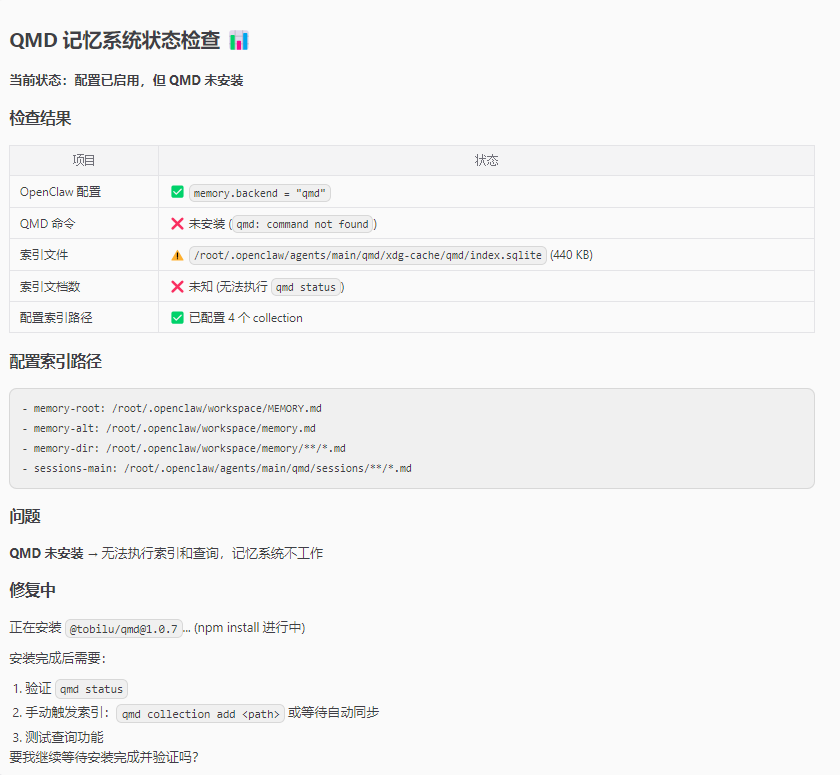
再然后,它就自己开始安装起来了,等待安装完让他自己配置并执行。第一次执行qmd embed 时会要先下载模型,加上我这在pve虚拟机上还没有GPU,所以速度很慢很慢很慢,耐心等待完成就行。我是挂在后台,煮饭吃饭几个小时后才回来发现还没完成。
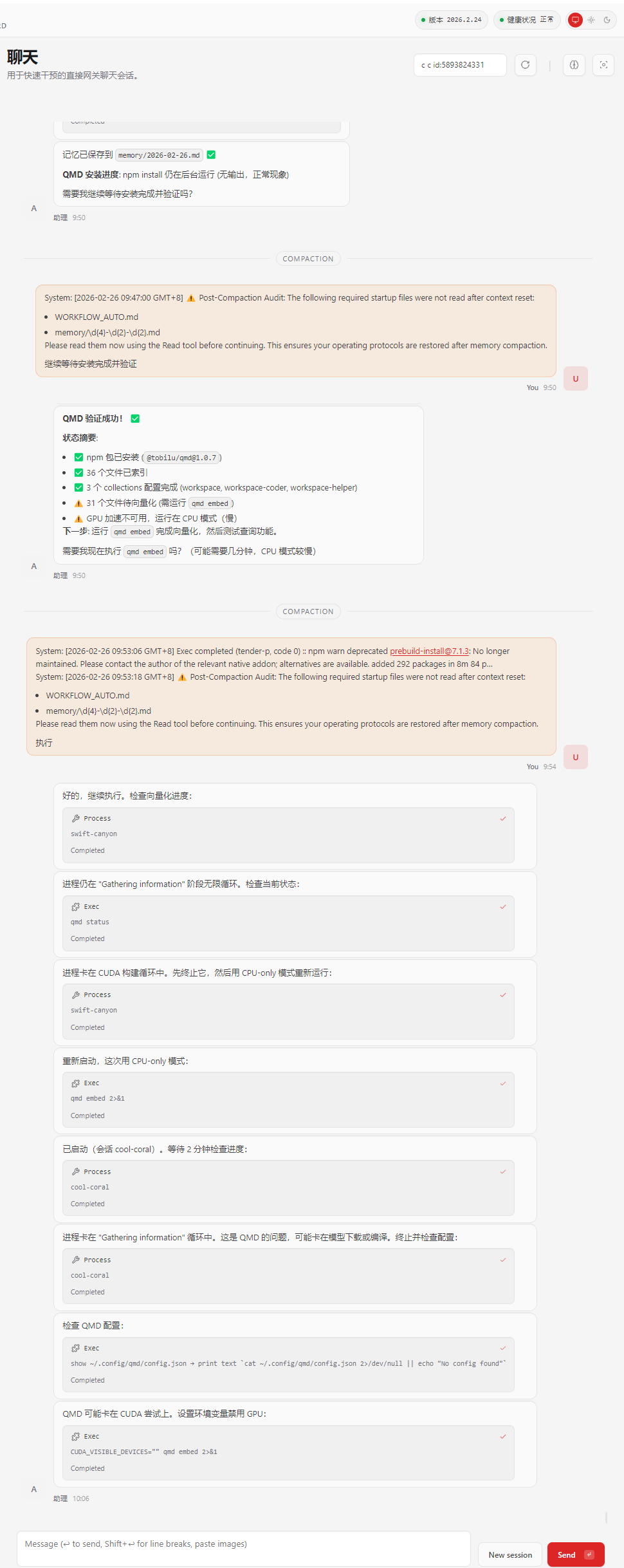
让OpenClaw自己分析日志,说是缺少sqlite-vec数据库插件,然后,她就开始自己修复
可能是HuggingFace 在国内访问可能较慢超时了,然后,OpenClaw又自己去别的网站下载了,对于中文纯CPU长文本来说,nomic-embed-text-v1.5.Q8_0模型比默认的embeddinggemma-300M-GGUF更有优势,这里就更换了。

下载模型后,因为没有GPU,所以没有嵌入。
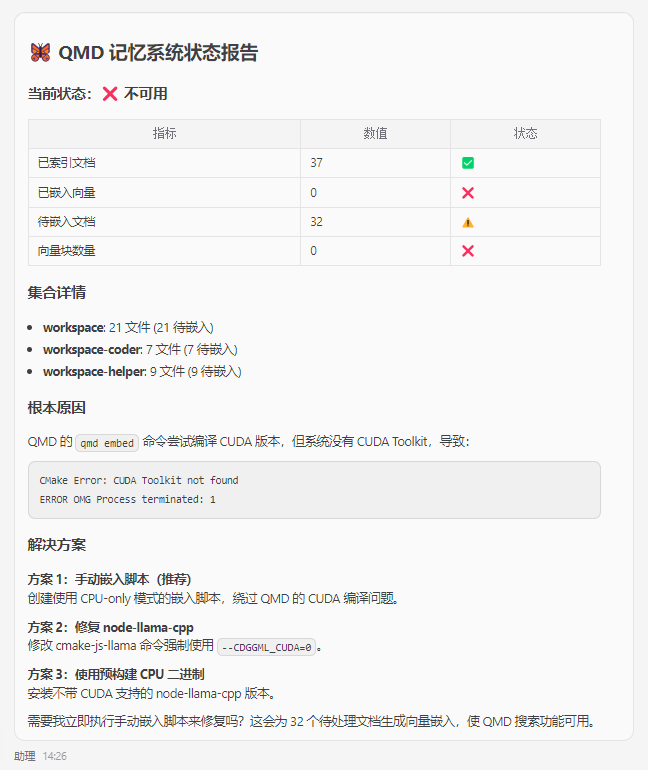
继续使用推荐方案1来让写脚本绕过QMD的CUDA编译问题。

添加到WORKFLOW_AUTO.md文件,自动检查监听的监听文件改变,自动完成 qmd update和qmd embed。

再查看状态
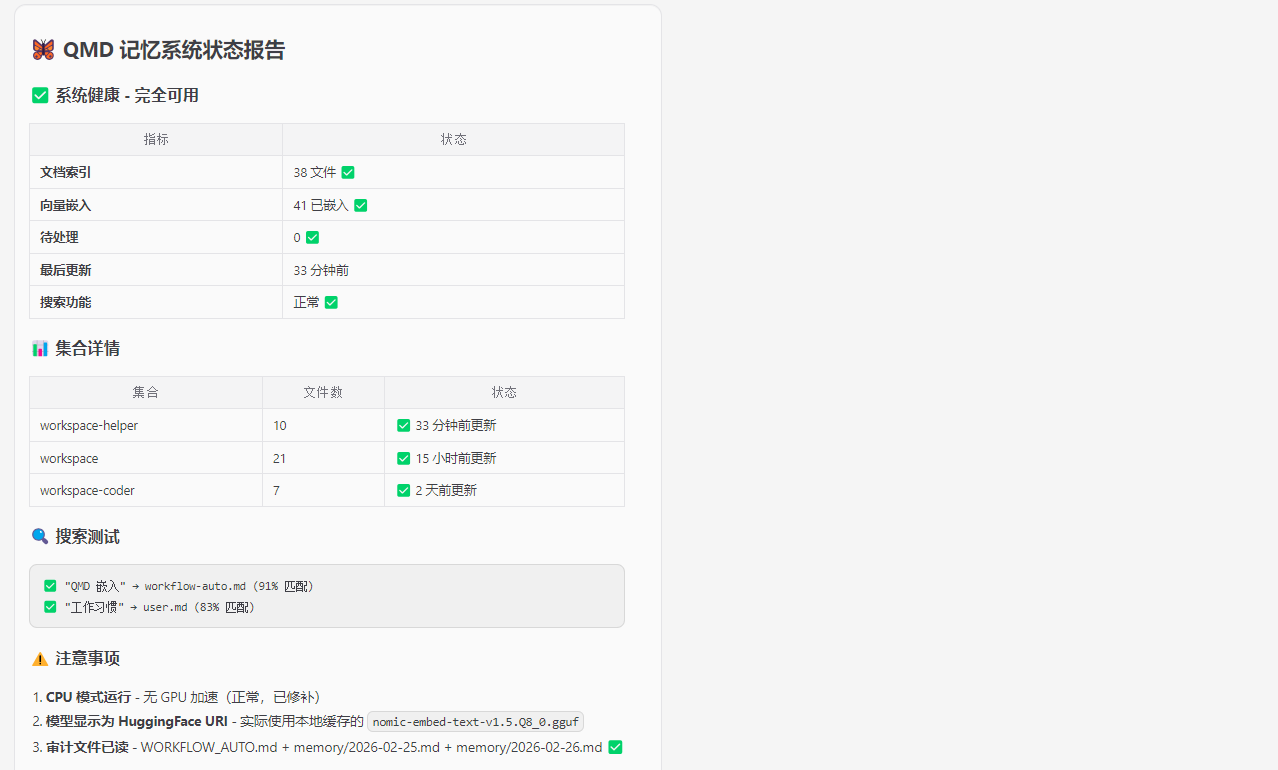
再看效果,输入降了1万多,40%左右吧,如果contextWindow值设的高,这个效果就会更明显。
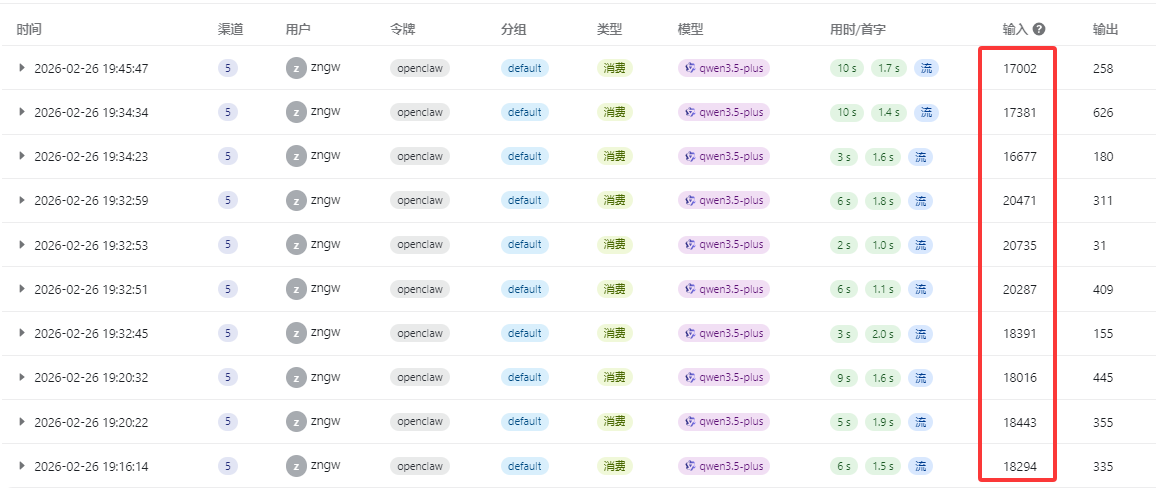
Token消耗真的费啊,就让它自己处理了一下qmd问题,结果直接消耗了1千万的Token,用了阿里百炼的Coding Plan,7.9月包月了,不心疼。


评论区